이번 글에서는 VM 기반의 kubernetes 클러스터에서 이미 설치한 Trino를 활용해 S3에 올라온 데이터를 읽어, 조회를 진행해 보겠습니다. 이를 진행하기 위해선 아래의 3가지의 환경이 이미 구성되어 있어야 합니다. (다른 글에서 다룰 예정)
1) ingress가 설정되는 환경이어야 합니다. (참고 - ingress-nginx-controller 설치)
2) Trino가 설치되어 있어야 합니다.
3) Hivemetastore가 설치되어 있어야 합니다. (참고 - Hivemetastore 설치)
Trino - S3 연결을 위해선 위의 3가지 환경이 사전에 구성되어 있어야 하며, 그 이유는 아래의 글에서 함께 설명을 진행하겠습니다.
우선, Trino를 좀 더 편한 환경에서 사용하기 위해선 Database tool을 사용하는 것이 좋습니다. kubernetes 환경에서 Trino를 사용하는 환경은 보통, Trino pod에 접속해 CLI를 활용하지만 불편한 점이 많이 있습니다. 이를 위해 가장 대중적인 Database tool인 DBeaver 를 사용하겠습니다.
따라서, DBeaver를 통해 Trino와 연결하고, DBeaver에 연결된 Trino를 통해 S3의 데이터를 가져오고, Query를 테스트 해볼 예정입니다.
DBeaver에서 Trino 연결하기
DBeaver에서 Trino를 연결하기 위해선 1) Trino의 Ingress-external IP가 설정되어 있어야 합니다. 또한, Port를 통해 접근할 예정이기에 2) Trino의 Service 리소스가 NodePort로 설정되어 있어야 합니다.
우선, DBeaver 설치/접속 후, "새 데이터베이스 연결"을 선택해줍니다.

이와 함께, DBeaver에서 Trino를 연결하기 위해선 Trino의 서비스 계정이 필요합니다. 아래와 같이 Trino의 서비스 어카운트 yaml 혹은 values.yaml (helm으로 설치한 경우)에서 serviceAccount를 설정해줍니다.

- create는 생성을 위해 true로 설정해줍니다.
- name은 편한대로 생성해주면 되나, 저는 간단하게 "trino"로 name을 Account name을 설정했습니다.
이제, DBeaver로 돌아와 conntection 설정을 진행해줍니다.
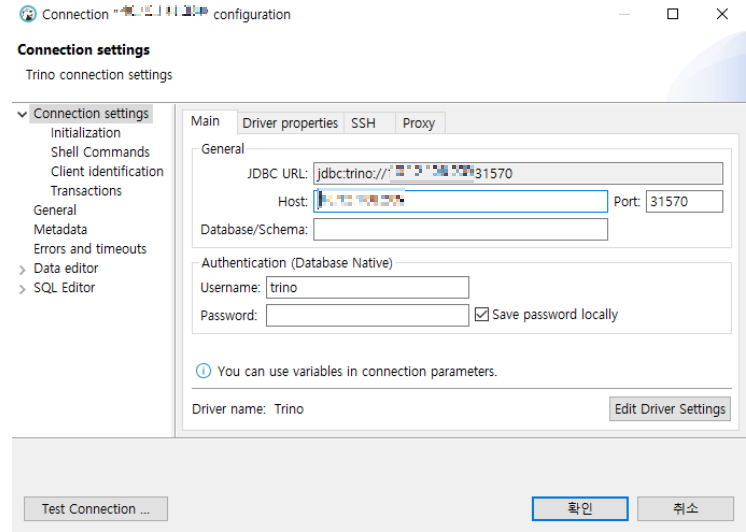
- JDBC URL은 Host, Port를 입력하면 자동으로 입력이 됩니다.
- Host는 Trino를 설치하는 과정에서 설정된 External-IP를 입력해주면 됩니다. (kubectl get services를 통해 Trino 서비스의 external-IP를 확인하거나, ingress-controller의 exteral-IP를 입력해주면 됩니다.)
- 즉, DBeaver가 Trino에 접근하기 위해선 외부에서 접근 가능하도록 설정되어 있어야 합니다.
- Port는 Trino의 NodePort를 입력해줍니다.
- Username은 이전에 설정한 serviceAccount를 입력해줍니다.
이제 위와 같이 설정을 마무리 했으면 Test Connection을 진행해줍니다. 단, 이 과정에서 Trino Driver가 설치되므로 1분~2분 정도의 시간이 소요됩니다. 정상적으로 connection이 확인되면, 아래와 같이 connected로 표시됩니다.

이후, 아래 이미지처럼 Trino connection이 확인이 됩니다.

이제 Trino를 통해 Query 및 Catalog를 테스트 해보겠습니다. 우선, 해당 connection의 SQL script를 열어주고, show catalog를 통해 Trino의 catalog list를 확인해봅니다.

catalog list를 확인해보면 기존에 설정한 kafka와 기본 catalog들이 생성/설정되어 있는 것이 확인됩니다.
AWS S3에 데이터(csv) 업로드 및 Hive catalog 설정
이제, DBeaver 환경은 세팅이 되었고, 본격적으로 S3에 있는 csv 데이터를 읽어와보겠습니다. 우선, S3(Object storage)에 airport라고 하는 csv 파일을 업로드를 진행합니다. (dataset - https://datahub.io/core/airport-codes)
디렉토리 구분을 위해 airport라는 디렉토리를 S3 버킷에 생성해주었고, 해당 디렉토리 하위에 위의 airport dataset을 업로드 진행했습니다.
추가적으로 Trino에서 Hive catalog를 생성해줄 예정입니다.
- Hive catalog를 생성하기 위해선 Hivemetastore가 설치되어 있어야 합니다.
- 그럼, 왜 Hivemetastore가 설치되어야 하는지 궁금해 하실 수 있는데, Trino에서 S3를 접근하기 위해선 Hive catalog를 통해 접근을 해야합니다.
- 즉, Hive를 통해 S3에 접근하여, 이를 Trino를 통해 읽어오는 방식입니다. <S3 - hivemetastore(Hive catalog) - Trino>
## trino-values.yaml(values.yaml)에서 설정
additionalCatalogs:
hive : |-
connector.name=hive
hive.metastore.uri=thrift://my-hms-hive-metastore:9083
hive.s3.aws-access-key=xxxxxx
hive.s3.aws-secret-key=xxxxxxx
hive.s3.ssl.enabled=false
hive.s3.path-style-access=true
hive.s3.endpoint=http://krcloud.s3.xxxx.co.kr
...
위와 같이 additionalCatalogs 하위에 hive catalog를 설정해줍니다.
- connector.name은 hive로 입력해줍니다.
- hive.metastore.uri는 hivemastore와 Port를 입력해줍니다.
- hive.s3.aws-access-key, secret-key, endpoint는 사용할 S3의 bucket에서 확인 후, 입력해줍니다.
이제, Trino를 update/re-install을 진행해준 후, Pod들이 정상적으로 올라와있는지 확인합니다.
$ kubectl get pods -n hivemetastore
NAME READY STATUS RESTARTS AGE
my-hms-hive-metastore-0 1/1 Running 0 84m
my-hms-postgresql-0 1/1 Running 0 84m
my-trino-coordinator-5d9bb8494d-vgdvl 1/1 Running 0 41s
my-trino-worker-799fdcccdd-gwc8d 1/1 Running 0 41s
my-trino-worker-799fdcccdd-swlbk 1/1 Running 0 41s
DBeaver에서 catalog 설정이 제대로 되었는지 다시 확인을 진행합니다. (Trino의 port가 계속 변경되는 이유는 설정과정에서 port를 고정하지 않아서 그렇습니다. 해당 변경이 번거로운 경우에는 port를 고정해주면 됩니다.)

이제, hive catalog를 통해 airport 데이터의 schema/table를 생성해주고 조회를 진행해보겠습니다.
## create schema
create schema hive.airport;
## table 생성
create table hive.airport.codes_4 (
ident varchar,
type varchar,
name varchar,
elevation_ft varchar,
continent varchar,
iso_country varchar,
iso_region varchar,
municipality varchar,
gps_code varchar,
iata_code varchar,
local_code varchar,
coordinates varchar
)
with (
external_location = 's3a://xxxx/airport/', #bucket에 생성한 디렉토리 기입
format = 'CSV' #데이터 포맷은 csv이므로 csv 기입
);
schema, table 생성 후 select query를 실행합니다.
- Hive schema 정보는 hivemetastore에 있으며, data source는 S3에서 받아오게 됩니다.
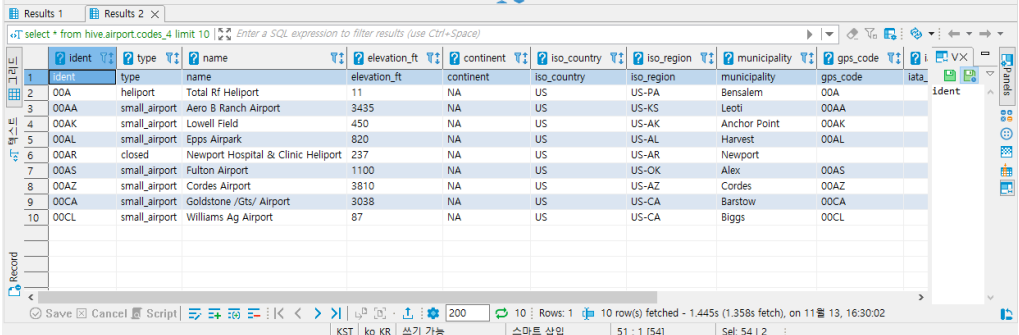
데이터가 정상적으로 조회가 되며, Trino Web ui에서도 query detail이 확인되는지 확인해줍니다.
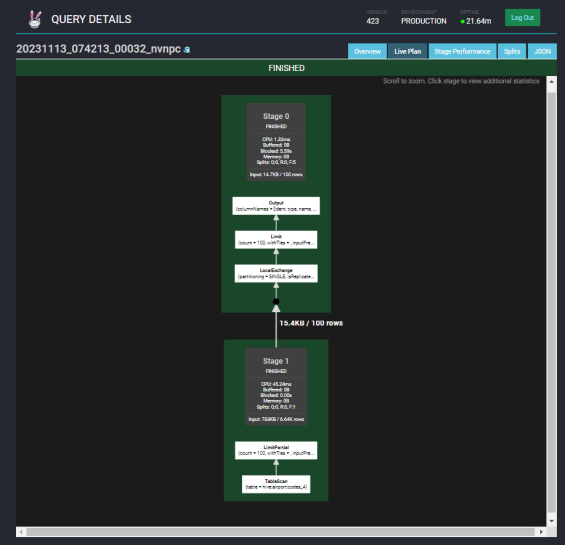
S3에서 json 조회 및 parsing
json 형태의 데이터를 S3에서 조회/parsing을 진행해보겠습니다.

{"rowNumber":1,"customerKey":1,"name":"Customer#000000001","address":"IVhzIApeRb ot,c,E","nationKey":15,"
phone":"25-989-741-2988","accountBalance":711.56,"marketSegment":"BUILDING","comment":"to the even, regular
platelets. regular, ironic epitaphs nag e"}
위와 같이 json형태로 되어있는 파일의 parsing을 진행합니다.
# spark schema를 생성해줍니다.
create schema hive.spark;
# json 데이터가 있는 path를 설정한 table을 만들어줍니다.
# column은 value 값을 하나의 column으로 우선 만들어줍니다.
CREATE TABLE hive.spark.customer (
value VARCHAR
)
WITH (
format = 'json',
external_location = 's3a://xxxxx/spark/'
);
# json_extract_scalar parsing을 이용해 조회를 진행합니다.
SELECT
json_extract_scalar(value, '$.rowNumber') AS rowNumber,
json_extract_scalar(value, '$.customerKey') AS customerKey,
json_extract_scalar(value, '$.name') AS name,
json_extract_scalar(value, '$.Customer') AS Customer,
json_extract_scalar(value, '$.address') AS address,
json_extract_scalar(value, '$.nationKey') AS nationKey,
json_extract_scalar(value, '$.phone') AS phone,
json_extract_scalar(value, '$.marketSegment') AS marketSegment,
json_extract_scalar(value, '$.comment') AS comment
FROM hive.spark.customer;
데이터 조회를 해보면 아래와 같이 Table 형태로 잘 조회가 가능하며, 이제 해당 결과를 기반으로 새로운 Table을 생성해주면 됩니다.

S3에서 데이터를 읽어오는 과정의 유의사항
S3에서 데이터를 읽어오는 과정에서 간혹, 아래와 같은 Error가 발생하는 경우가 있습니다.
TrinoException: Unable to execute HTTP request: Read timed out at io.trino.plugin.hive.BackgroundHiveSplitLoader$HiveSplitLoaderTask.process(BackgroundHiveSplitLoader.
java:321)
위의 경우는 보통, S3의 어떤 데이터를 읽어와야 할지 모르는 경우에 발생하게 됩니다. 즉, bucket안의 디렉토리 하위에 여러 파일이 혼재되어 있는 경우 디렉토리 안에서 어떤 파일을 읽어야 할지 모르는 경우 발생하게 됩니다.
이러한 경우 "external_location"에서 설정한 디렉토리 하위에 읽을 파일들만 남겨놓으면 해결되게 됩니다. 즉, airport.csv 파일을 읽어 조회하는 경우라면 해당 csv 파일만 남겨놓고 다시 진행을 하면 해결이 될 가능성이 높습니다.

ref
- https://trino.io/docs/current/connector.html
Connectors — Trino 437 Documentation
trino.io
- https://developnote-blog.tistory.com/187
Trino 한번 써보겠습니다(3) - AWS S3내 CSV 데이터 조회
Trino 한번 써보겠습니다(3) 분산 Query Engine 중 가장 핫한 Trino를 설치해 보았습니다. Kubernetes Cluster에 Hive Metastore를 구성해서 AWS S3에 연결까지 해보았습니다. Trino 한번 써보겠습니다(2) - Hive Metastore
developnote-blog.tistory.com
- https://janakiev.com/blog/presto-trino-s3/
Querying S3 Object Stores with Presto or Trino
Querying big data on Hadoop can be challenging to get running, but alternatively, many solutions are using S3 object stores which you can access and query with Presto or Trino. In this guide you will see how to install, configure, and run Presto or Trino o
janakiev.com
'kubernetes' 카테고리의 다른 글
| [kubernetes] Hive metastore 설치 및 설정 (hive-s3 connector for trino) (1) | 2024.02.04 |
|---|---|
| [kubernetes] ingress-nginx-controller (helm) 설치 및 ingress 리소스 설정 (1) | 2024.01.21 |

