이번 글에서는 Trino라는 분산 SQL 쿼리 엔진을 실제 사용하며, 알게된 점 그리고 궁금했던 점들을 정리해 게시할 예정입니다. 해당 글에서는 Trino의 기본적 개념 정리와 동작 방식의 이해를 목표로 합니다.
Trino란
Trino는 하나 이상의 heterogeneous (서로 다른 종류의 개별) data sources에 분산된 대규모 데이터 세트를 쿼리하도록 설계된 오픈소스 분산 SQL 쿼리 엔진입니다. 우선, Trino는 관계형 데이터베이스가 아닙니다. 즉, Mysql, Oracle SQL과 같은 데이터베이스를 대체하지 않습니다. 여담으로 Trino는 기존 Facebook의 Presto 초기 멤버들이 페이스북을 나와 만든 PrestoSQL 프로젝트가 Trino 라는 이름으로 리브랜딩 되었습니다.
Trino 특징 및 쿼리 엔진
일반적으로 trino는 기존의 hive, spark 인프라에서 느린 쿼리 처리 속도를 경험할 때, 사용을 고려하게 됩니다. Trino의 기원인 Presto 또한, 2012 년 Facebook에서 이러한 느린 Hive 쿼리 환경으로 인해 발생했습니다. 하지만 Trino에 Hive 커넥터가 있는데, Hive의 속도 저하를 피하기 위해 Trino로 이동했다는 측면에서 혼란스럽게 생각될 수 있는 부분입니다. (자 세한 내용은 아래에서 설명 예정) Trino는 분산 SQL 쿼리 엔진을 통해 빠른 성능을 자랑합니다.
세부 연산 과정
Trino의 분산 SQL 쿼리 엔진은 분산 방식으로 서버 클러스터에 모든 처리를 분산 합니다. 더 많은 처리 능력을 얻기 위해 Worker 노드를 추가할 수 있음을 의미합니다. 예를 들어, 하나의 Worker가 Cordinator에게 데이터를 제공할 수 있을 때까지 여러 Worker들이 데이터 소스에서 데이터를 검색하고 Worker들 이 협업하여 데이터를 처리합니다.

Trino에는 Cordinator, worker와 통신하여 Data source에서 데이터를 읽어 올 수 있도록 하는 Connector가 존재합니다. Connector는 특정 데이터 소스와 관련된 세부 정보를 처리합니다.
- 1. 테이블/뷰/스키마 메타 데이터를 가져오는 작업
- 2. Trino가 읽기 및 쓰기를 병렬화할 수 있도록 데이터 분할의 논리 단위를 생성하는 작업
- 3. 소스 데이터를 쿼리 엔진에서 예상하는 In-memory 형식 (Memory-to-Memory data transfer)으로 변환하는 데이터 소스 및 싱크)
Trino의 분산 SQL 쿼리 실행 엔진은 우선, Coordinator 내부에서 어떤 로직이 돌아가는지 살펴봐야 합니다. SQL 문이 Coordinator에게 제출이 구문 분석을 진행합니다. 이후 쿼리 계획이라는 실행 계획을 생성합니다. 쿼리 계획은 데이터를 처리하고 SQL문에 따라 결과를 반환하는데 필요한 Stages를 나타냅니다.

Coordinator는 전체 쿼리 속도를 높이기 위해 병렬로 Worker가 클러스터에서 처리할 수 있도록 계획을 나눕니다. Stage 수는 쿼리의 복잡성에 따라 다릅니다.

분산 쿼리 계획은 Trino에서 쿼리가 실행되는 Stage와 방법을 정의하며, Coordinator가 worker 전체의 Task를 추가로 계획하고 Reserved 하는데 사용합니다. Stage는 하나 이상의 Task로 구성되며, 일반적으로 각 Task는 데이터의 일부를 처리합니다.

Task가 작업을 처리하는 데이터 단위를 Split라고 하며, 병렬 처리 및 Task 할당의 단위입니다. 이러한 모든 연산들은 아래 그림과 같이, 서로 다른 Worker에서 병렬로 발생합니다.

즉, Task는 Worker에게 할당될 때, 하나 이상의 드라이버를 사용할 수 있으며, 모든 Driver가 완료되고, 다음 Split으로 전달되면 Driver와 Task이 파기됩니다. Operator는 입력 데이터를 처리하여 Down stream Operator에 대한 출력 데이터를 생성하며, Operator의 예로는 테이블 스캔, 필터, 조인 및 집 계가 있습니다. 이러한 연속적 Operator는 Operator pipeline을 형성합니다. 예를 들어, 먼저 데이터를 스캔하고 읽은 다음 데이터를 필터링하고 마지막으로 데이터에 대한 부분 집계를 수행하는 파이프라인이 있을 수 있습니다.

연산 과정 정리
- 쿼리를 처리하기 위해 Coordinator는 Connector의 Metadata를 사용하여 Split 목록을 만듭니다.
- Coordinator는 Split 목록을 사용하여 데이터를 수집하기 위해 Worker에 대한 Task 예약을 시작합니다.
- 쿼리 실행 중, Coordinator는 Processing에 사용할 수 있는 Worker에서 running 중인 Tasks와 Splits의 위치를 추적합니다.
- Task 처리를 완료하고 Down stream 처리를 위해 더 많은 Split을 생성함에 따라 Coordinator는 처리할 Split이 남아있지 않을때까지 Stage를 지속 예약합니다.
- Worker에서 모든 Split이 처리되면, 데이터를 사용할 수 있게되고, Coordinator는 결과를 Client에게 전달합니다.
Trino는 데이터베이스(DB)인가?
결론부터 말하면, Trino는 데이터베이스(DB)가 아닙니다. Trino는 객체 스토리지 시스템 (AWS S3, GCP 등), 관계형 데이터베이스 (Mysql, Oracle, MSSQL 등), Nosql 시스템 (Kafka, MongoDB, E/S 등) 및 기타 시스템에서 데이터를 쿼리할 수 있는 "쿼리 엔진"입니다.
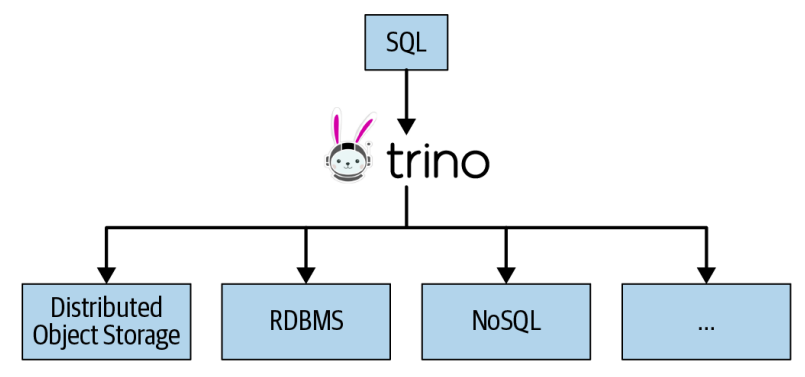
Trino는 스토리지가 있는 데이터베이스가 아니며, 데이터가 있는 위치에 데이터를 쿼리합니다. Trino를 사용할 때, 스토리지와 컴퓨팅은 분리되어 독립적으로 확장되며, Trino는 컴퓨팅 계층을, 기본 데이터 소스는 스토리지 계층을 나타냅니다. RDBMS 및 기타 데이터 저장 시스템을 모두 지원하므로 Trino를 사용하여, 데이터를 이동이 가능합니다. SQL을 사용하여 데이터를 쿼리하고 변환한 다음 동일한 데이터 원본이나 다른 데이터 원본에 사용할 수 있습니다. 예를 들어, 객체 스토리지 시스템에서 RDBMS로 데이터를 복사가 가능합니다.
Trino의 특징 정리
- 속도 : 분산 쿼리 엔진을 기반으로 빠른 속도를 나타냅니다.
- 사용성 : 표준 쿼리(Ansi-sql) 방식의 엔진과 BI도구를 제공하여 사용이 편리합니다.
- 연결 : 다양한 connector를 제공하여 연결 및 사용이 용이합니다.
Trino와 Hive
위의 설명과 같이, Trino는 Hive의 느린 쿼리 환경을 개선하기 위해 고안되었습니다. 그러나 Trino의 Connector 목록에 Hive가 있는 것이 의아하게 생각될 수 있습니다. 결론부터 말하면 Trino의 Hive Connector는 Hive의 Runtime 코드를 사용하지 않습니다.
이를 알기 위해, Hive의 아키텍쳐를 간단하게 살펴보며, 설명을 이어가겠습니다.
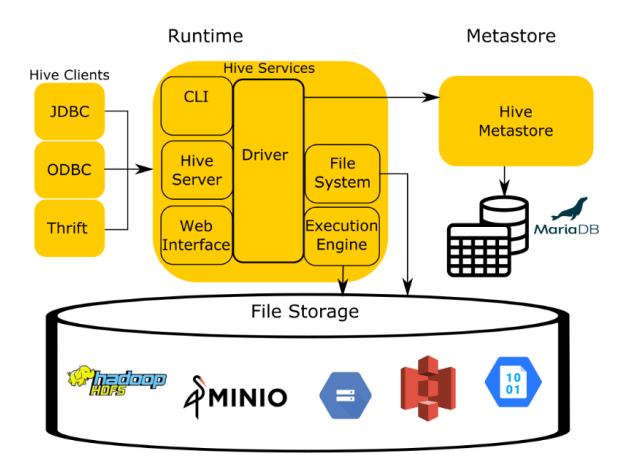
Hive 아키텍처는 크게 4가지 구성요서로 단순화할 수 있습니다. Runtime 영역을 보면, client가 제출한 HQL을 Hive-server2가 앞단에서 받게 되고, 이를 Driver에게 전달합니다. Hive-server2는 권한과 접근성 검증을 체크합니다. Driver는 여러 질의를 받아 컴파일러에게 쿼리 플랜 요청 보내고 받으며, Compiler는 Metastore와 통신하며 쿼리에 필요한 메타정보를 주고 받습니다.
이후 Compiler는 쿼리에 대한 metadata를 Metastore로 부터 밭아 Execution plan을 생성하고, 이를 Driver에게 전달합니다. 실행 엔진 (Execution Engine, (MR, Tez, Spark))은 Driver에게 Execution plan을 전달 받아, hadoop 모듈과 통신하며 Map / Reduce job을 실행합니다.
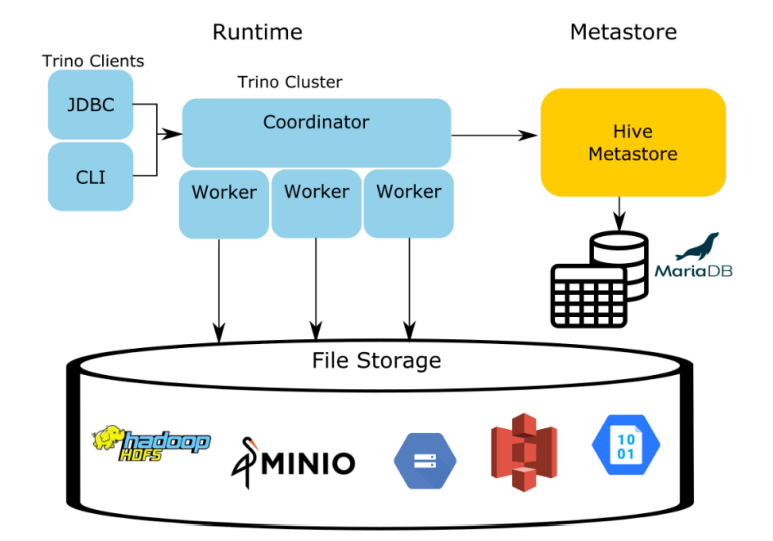
그림 이제 Trino로 다시 넘어와, 설명을 이어가겠습니다. Trino는 Hive의 런타임 영역을 대체하고, Hive의 Metastore(테이블 스키마)만을 사용하게 됩니다. 즉, HiveMetastore는 Hive connector를 사용하게 될 때, 기존 Hive 프로세스 중에 유일하게 활용되는 컴포넌트입니다. 여기서 connector의 위치는 worker와 File storage (Data source) 사이에 위치하며, 데이터 소스에서 데이터를 읽을 수 있도록 Coordinator, Worker와 통신하며, 데이터소스를 연결해주는 역할을 합니다.
실제로, Trino를 사용하는 경우, HiveMetastore만 따로 설치해, 스토리지는 S3, 테이블스키마는 Hivemetastore를 사용하는 경우가 많습니다.
reference
Use cases — Trino 435 Documentation
Use cases This section puts Trino into perspective, so that prospective administrators and end users know what to expect from Trino. What Trino is not Since Trino is being called a database by many members of the community, it makes sense to begin with a d
trino.io
'Bigdata Components > Trino' 카테고리의 다른 글
| [Trino] Trino의 Trino web UI와 성능 비교 (1) | 2024.01.07 |
|---|---|
| [Trino] Trino의 구조 및 설정 (0) | 2024.01.07 |

